
Completely Automated Public Turing test to tell Computers and Humans Apart AKA Captchas (You get a virtual cookie for reading all of that.) Are those pesky data pipeline cloggers stopping your web scraping tools from getting the job done efficiently.
They’re the pawns used by websites to disable you from doing what you do best, gather data.
In this ProxyEmpire tutorial, we will teach you how to mitigate data loss due to CAPTCHAs or avoid them altogether. You will know what triggers them, how to get around their tests and stop running into so many CAPTCHAs with your web crawler.
The Purpose And Nature Of CAPTCHAs
The main reason that webmasters implement CAPTCHAs is to parse between human and robotic traffic. This is accomplished by placing a challenge that would be easy for a human to complete but very difficult for a bot. By doing this, webmasters can filter out DDoS attacks, spam, and web scraping.
If you have ever scanned papers and converted them to editable text you will be familiar with optical content recognition technologies. Originally CAPTCHAs were implemented as a way for computers to learn to read writing through the assistance of humans filling out the information.
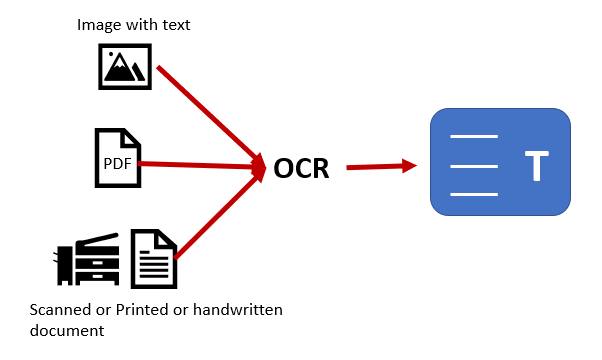
Google uses us as the beast of burden to assist in it’s machine learning program.
They can appear under a variety of circumstances like when the website detects unusual traffic or another signal triggers them. Dedicated signup pages and checkout carts usually have CAPTCHAs without any trigger mechanism. Ultimately, it comes down to the decision of the Webmaster.
Understanding CAPTCHA Triggers
Platforms implement a variety of ways to determine risk and have algorithms in place to introduce CAPTCHAs into your life depending on those risk parameters. Here are a couple of triggers listed below and how they function so that you can avoid them.
Network Triggers
If you are using an office network, public Wifi, or abused proxies – this will result in a CAPTCHA loading. Datacenter proxies are shared among dozens of users and are often used for nefarious reasons. Even if the proxies are clean, it is easy to spot that the IP address is from a data center.
Fingerprinting
This is the process of identifying unique characteristics about you and turning that information into a “fingerprint”. The data collected on you to do this is usually user agents, HTTP headers, TCP/IP data, and TLS. This is the one reason even if you change IP addresses, some platforms still know it is you.
Javascript Logging
Rarely is this implemented, but surprisingly enough Amazon does indeed use scripts to create a unique profile identifying you. Scripts aim to log your computer’s hardware manufacture numbers and router MAC address. It is invasive, to say the least.
These triggers do not have to give you a captcha to solve, rather they can just block you from the platform outright. The most common of these triggers is the network restriction option. That is why you will not see people using data center proxies for Instagram.
Overview Of CAPTCHA Challenges While Web Scraping
Web platforms implement a variety of CAPTCHA types and each one is designed to block automation. Some are more elaborate than others. One thing is for sure, each CAPTCHA style can throw a wrench in your data scraping operations.
Text entry CAPTCHAs
This style is the oldest around and is rarely implemented these days because it’s hard for the user to guess the letters, but with optical recognition, bots can fill them out easily.
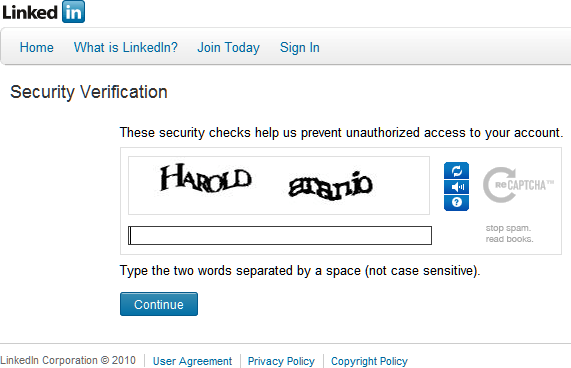
As artificial intelligence increases and machine learning advances, you will see this style of CAPTCHA dwindle, especially on major web platforms. The only major platform that it’s used today would be Amazon which stubbornly has its unique CAPTCHA program.
Image Recognition CAPTCHAs
Nowadays these are the most common style CAPTCHA you will see across the web. Of course, the goal is for the user to identify a series of objects that are similar or different depending on the question that is given in the CAPTCHA itself.
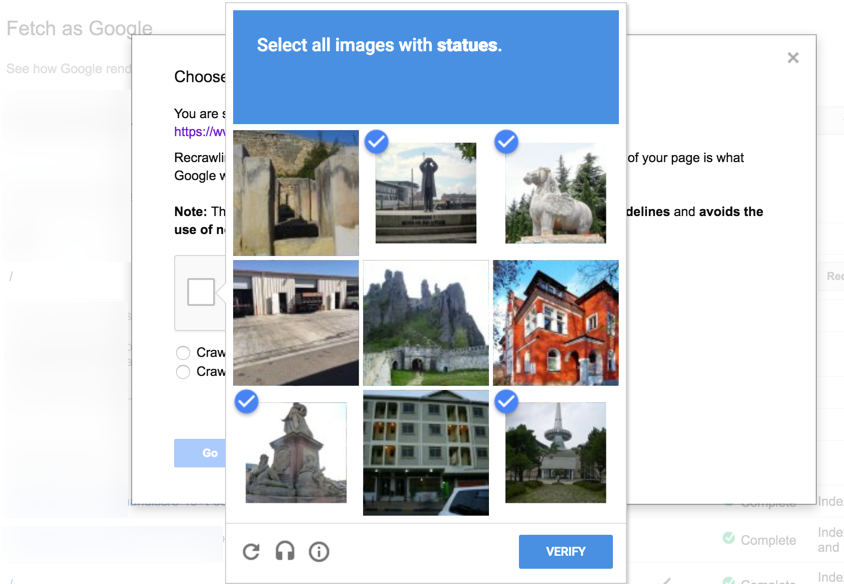
Unlike text entry versions this captcha is harder for machine learning to grasp but easier for humans. Some of them are more sophisticated in that they show multiple pages of images forcing the user to wait for a refresh which makes automating its completion more difficult.
One-click CAPTCHAs
In popularity, these rival image identification CAPTCHAs and are sometimes referred to as noCAPTCHAs because technically all you have to do is click a box. They are mainly triggered by network signals that are deemed fraudulent to the platform.
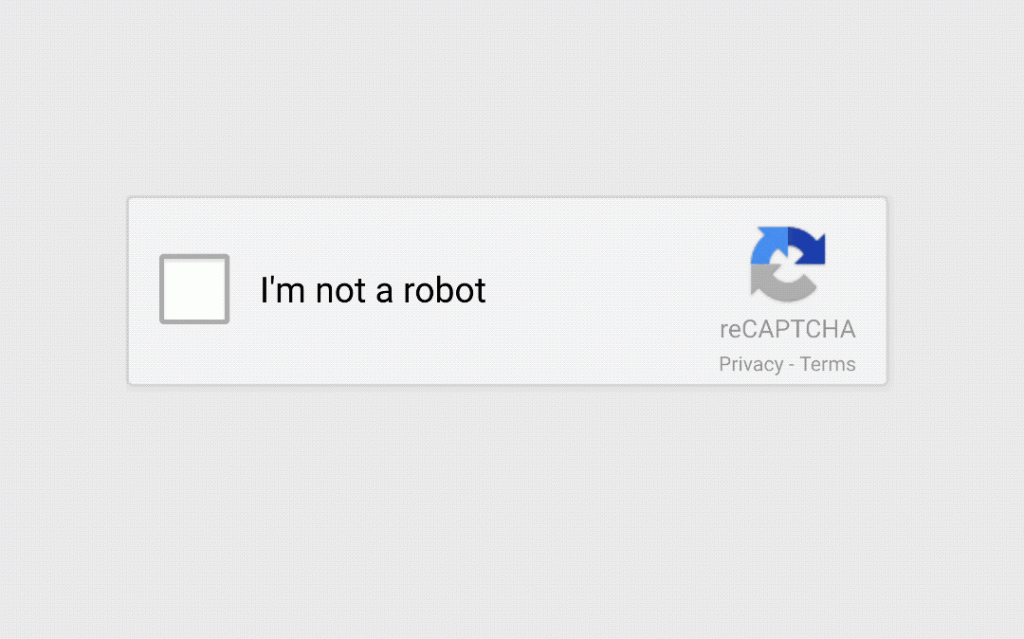
They rely on behavioral traits to see if you are a bot or human. If you pass the test you will proceed to the content, however, if you fail you will have to fill out an image recognition CAPTCHA. Usually, they can be avoided by having a solid network behind your web scraper.
reCAPTCHA Version 3 (Invisible CAPTCHA)
Essentially these are the same as one-click CAPTCHAs but they are not supposed to be seen at all by the user and rely on JavaScript to identify if you are a threat or not. Remember how earlier in this tutorial we taught you that scripts can log your system’s information.
This information is then evaluated to determine if your network is from a data center, you’re repetitively visiting from the same hardware, and if you’re using the platform’s bandwidth. If you fail the test you may be banned from entry, shown limited content, or forced to solve one of the CAPTCHAs listed above.
Bypassing CAPTCHAs With ProxyEmpire
The best way to deal with CAPTCHAs is to simply not proc them in the first place. That is because some platforms just show you limited content that your web scraper picks up instead of solving a CAPTCHA. This can be accomplished with advanced cloaking mechanisms that serve your web scraper false content.
With a VPN, data center proxies, or a small static residential network you can easily be flagged. This is the result of the network being shared among many users and with simple inspection a platform can determine the traffic is from a datacenter and not from an actual person.
You can do the same thing manually with a reverse IP address lookup…
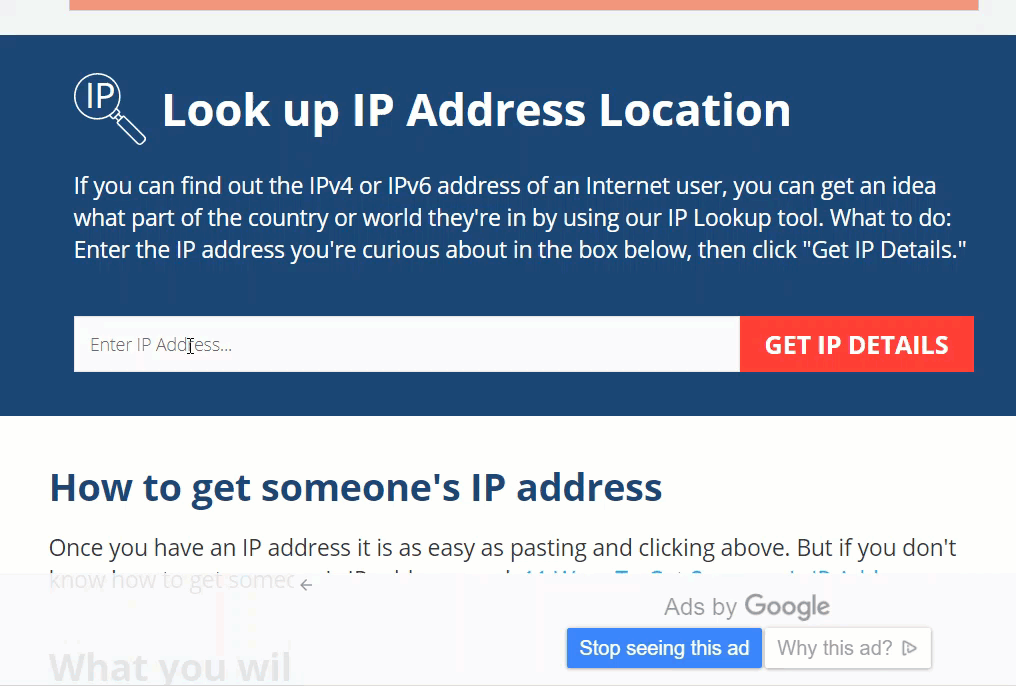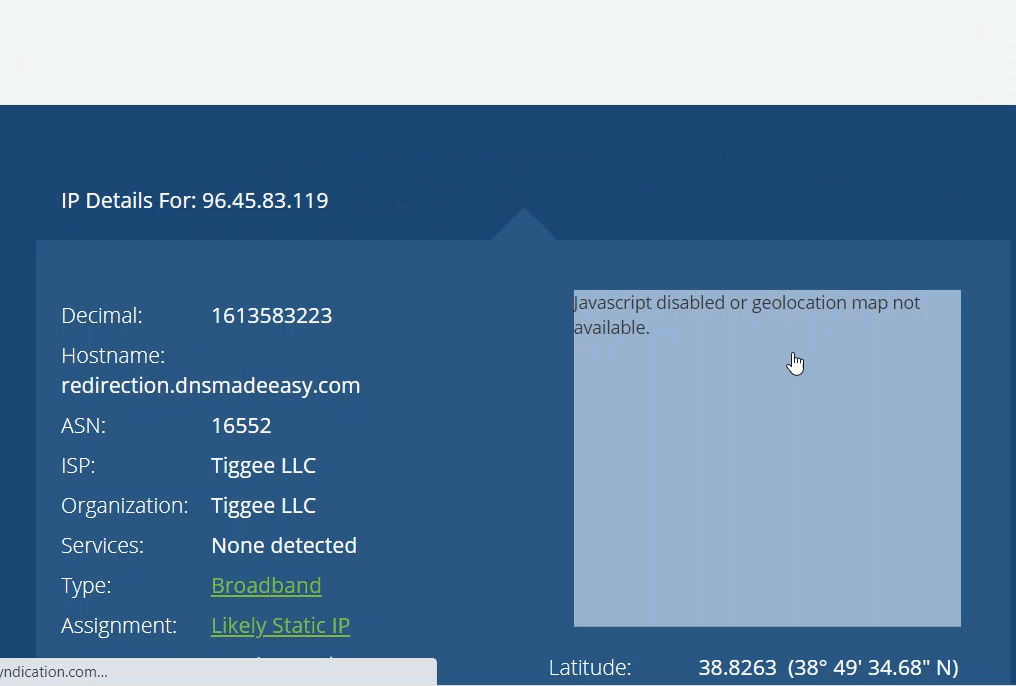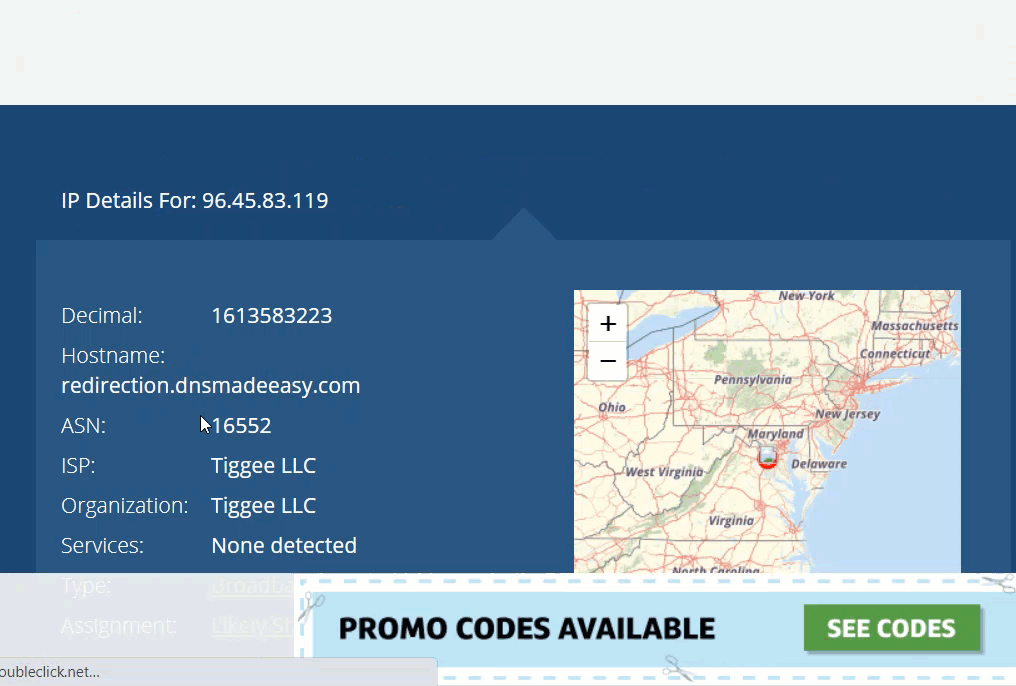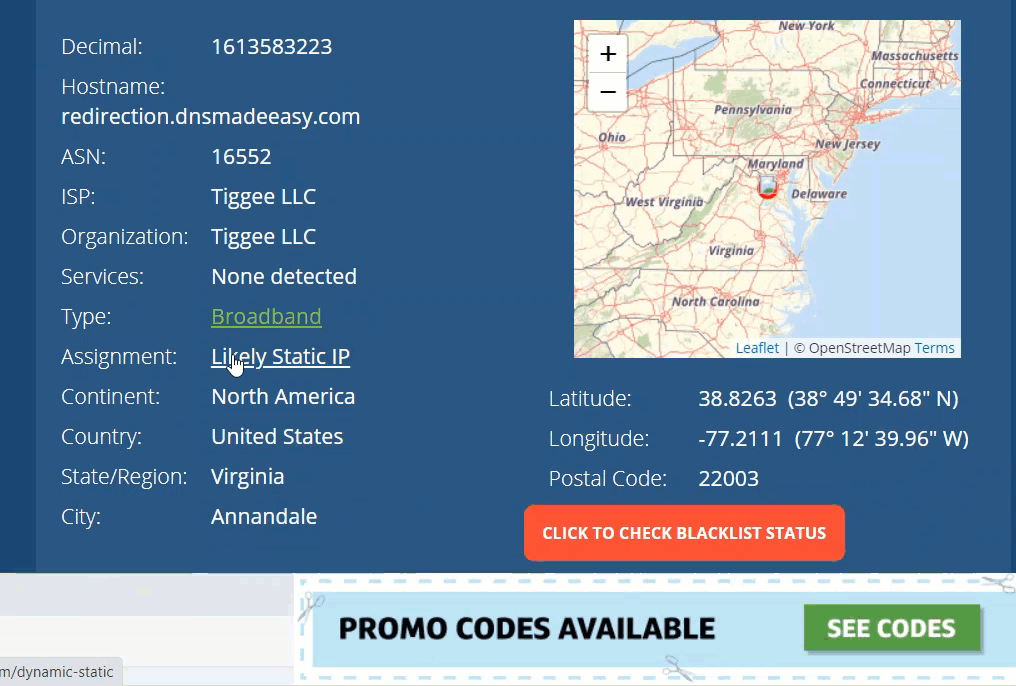
To stop CAPTCHAs from loading in the first place you should use high-quality residential and mobile proxies that are only used for certain use cases.
Residential proxies and mobile LTE proxies come from domestic Internet providers. When used with your web scraper you will mimic the residence itself tricking the platform into believing you are a real person and not a bot.
GEO-location Circumvention
Most people do not know that some network triggers (As outlined above.) are caused by location discrepancies rather than the quality of your IP address. This is especially true for our sneaker friends who are targeting sales in a specific location.
If a platform is expecting you to connect to it from a targeted location, then you must give it exactly what it wants. If you’re running into a lot of CAPTCHAs consider implementing advanced filters within your ProxyEmpire dashboard.
You can target 150+ countries, regions, cities, and ISPs.
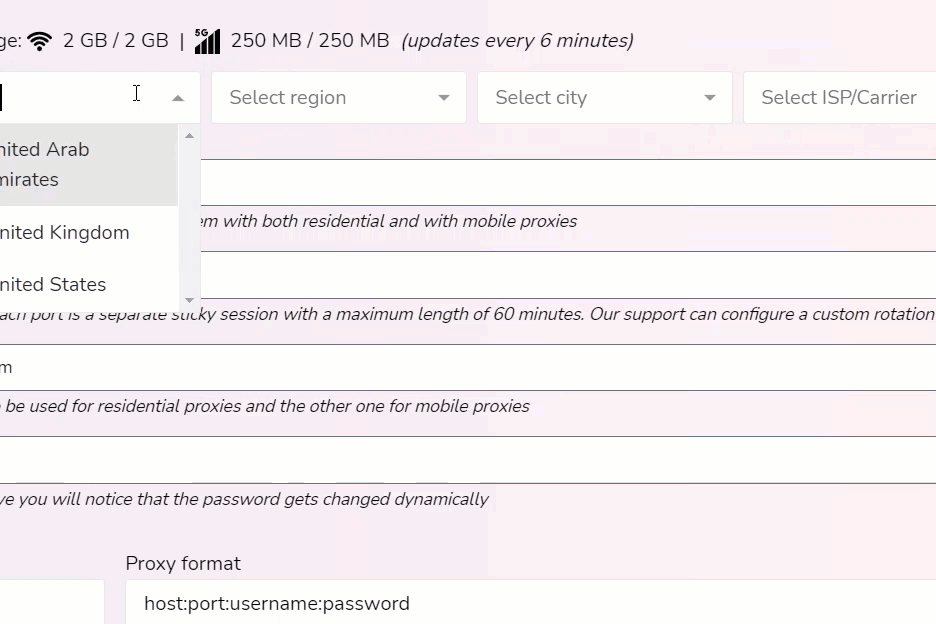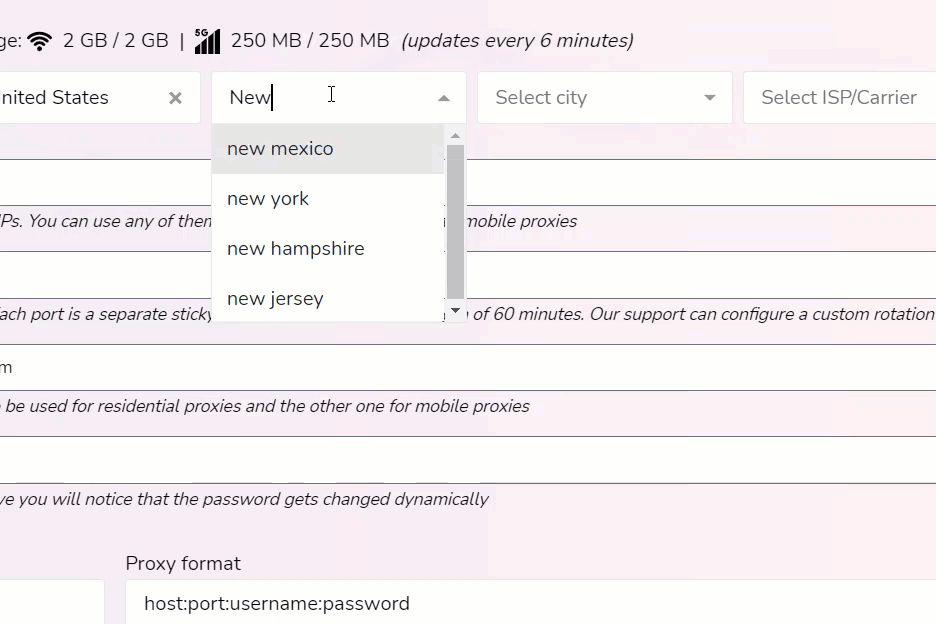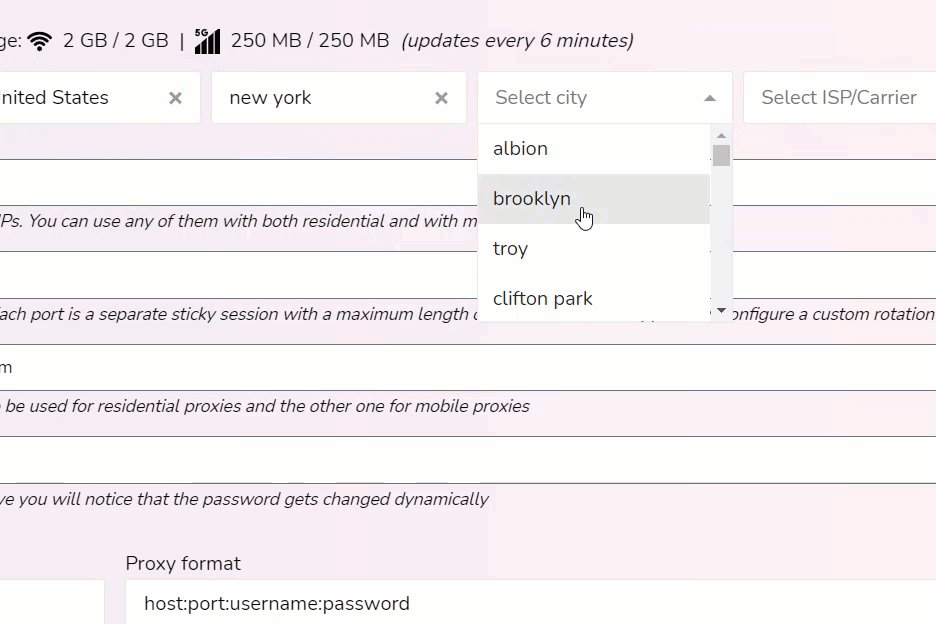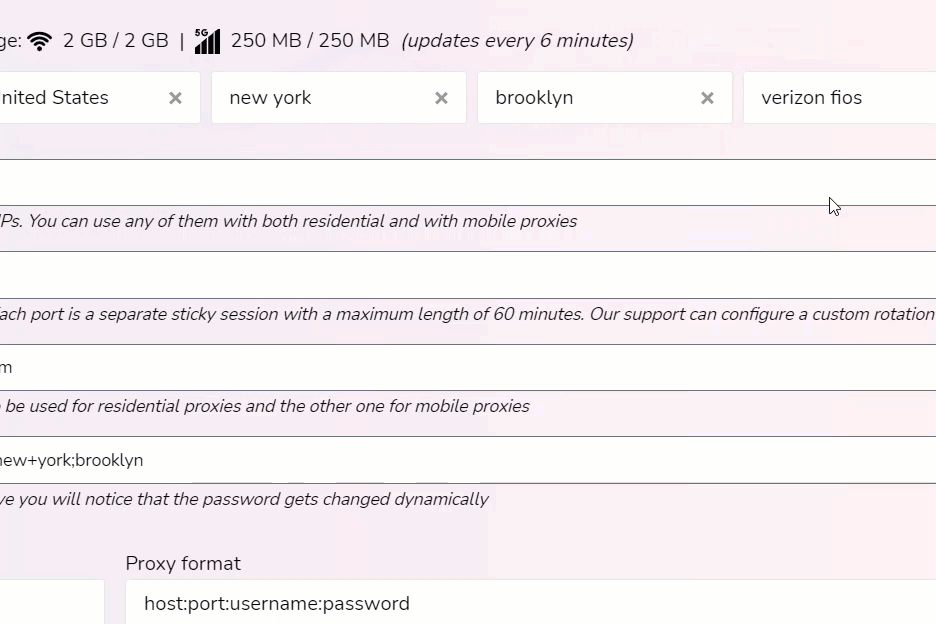
For example, if my web scraper was set to gather data in the city of Toronto. I would simply select Canada, Ontario, and then the city of Toronto. If you want to be granular you can research what ISP is used within a city section and choose it.
Setting Rotation Times
Big data requires a big network that can work alongside your web scraping efforts. if you are still encountering CAPTCHAs, consider setting a faster rotation time. Increasing the rotation gives you faster access to high-quality IP addresses.
For now, this can simply be accomplished by contacting ProxyEmpire support.
Please be aware that the average session length per node is currently 15 minutes. We can however set the rotation time from one minute up to the max of 60 minutes. That does not guarantee session length, however it does force rotation.
Solving Unavoidable CAPTCHAs
Machine learning has increased the flags used to determine if you should fill out a CAPTCHA, that same technology also works in your favor. Traditionally you would pay microworkers or services to solve the various types of tests given.
If you have a programmer within your company you can consider using Amazon’s “Rekognition” neural network that learns how to solve even the most complex CAPTCHAs.
The neural network would have to be integrated into your web scraper software. We realize that solution is not for everyone and for those of you who cannot take advantage of a neural network we recommend CAPTCHA solving services.

2captcha
This service has been around for a long time, works off of an API, and will set you back about $3 per 1000 one-click CAPTCHAs.

Death by CAPTCHA
A solid service that can solve text, image, and one-click CAPTCHAs. Comes with an API for integration.
We are not officially sponsoring these services, but they have been around long enough to recommend them as possible solutions. 2CAPTCHA and DeathByCaptcha pair well with residential proxies from ProxyEmpire.
Looking Forward
Artificial intelligence and big data will only increase the sophistication of triggers used to throttle web scrapers. It is now time to fight back with a robust residential proxy network and the implementation of neural networks to solve unavoidable CAPTCHAs.
At ProxyEmpire we hope that this tutorial helps your web scraping efforts and would like to make it easier for you to bypass CAPTCHAs today by offering you a trial.
If you have any questions, remember that our hero-level support is located in the bottom right-hand corner of your screen within the live chat.


















